Table of Contents

Table of Contents
IEEE Press
445 Hoes Lane
Piscataway, NJ 08854
IEEE Press Editorial Board 2012
John Anderson, Editor in Chief
| Ramesh Abhari | Bernhard M. Haemmerli | Saeid Nahavandi |
| George W. Arnold | David Jacobson | Tariq Samad |
| Flavio Canavero | Mary Lanzerotti | George Zobrist |
| Dmitry Goldgof | Om P. Malik |
Kenneth Moore, Director of IEEE Book and Information Services (BIS)
Technical Reviewers
Xuemei Zhang
Principal Member of Technical Staff
Network Design and Performance Analysis
AT&T Labs
Rocky Heckman, CISSP
Architect Advisor
Microsoft

cover image: © iStockphoto
cover design: Michael Rutkowski
ITIL® is a Registered Trademark of the Cabinet Office in the United Kingdom and other countries.
Copyright © 2012 by the Institute of Electrical and Electronics Engineers. All rights reserved.
Published by John Wiley & Sons, Inc., Hoboken, New Jersey.
Published simultaneously in Canada.
No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Section 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, Inc., 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 750-4470, or on the web at . Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 111 River Street, Hoboken, NJ 07030, (201) 748-6011, fax (201) 748-6008, or online at .
Limit of Liability/Disclaimer of Warranty: While the publisher and author have used their best efforts in preparing this book, they make no representations or warranties with respect to the accuracy or completeness of the contents of this book and specifically disclaim any implied warranties of merchantability or fitness for a particular purpose. No warranty may be created or extended by sales representatives or written sales materials. The advice and strategies contained herein may not be suitable for your situation. You should consult with a professional where appropriate. Neither the publisher nor author shall be liable for any loss of profit or any other commercial damages, including but not limited to special, incidental, consequential, or other damages.
For general information on our other products and services or for technical support, please contact our Customer Care Department within the United States at (800) 762-2974, outside the United States at (317) 572-3993 or fax (317) 572-4002.
Wiley also publishes its books in a variety of electronic formats. Some content that appears in print may not be available in electronic formats. For more information about Wiley products, visit our web site at .
Library of Congress Cataloging-in-Publication Data:
Bauer, Eric.
Reliability and availability of cloud computing / Eric Bauer, Randee Adams.
p. cm.
ISBN 978-1-118-17701-3 (hardback)
1. Cloud computing. 2. Computer software–Reliabillity. 3. Computer software–Quality control. 4. Computer security. I. Adams, Randee. II. Title.
QA76.585.B394 2012
004.6782–dc23
2011052839
To our families and friends for their continued encouragement and support.
FIGURES
| Service Models | |
| OpenCrowd’s Cloud Taxonomy | |
| Roles in Cloud Computing | |
| Virtualizing Resources | |
| Type 1 and Type 2 Hypervisors | |
| Full Virtualization | |
| Paravirtualization | |
| Operating System Virtualization | |
| Virtualized Machine Lifecycle State Transitions | |
| Fault Activation and Failures | |
| Minimum Chargeable Service Disruption | |
| Eight-Ingredient (“8i”) Framework | |
| Eight-Ingredient plus Data plus Disaster (8i + 2d) Model | |
| MTBF and MTTR | |
| Service and Network Element Impact Outages of Redundant Systems | |
| Sample DSL Solution | |
| Transaction Latency Distribution for Sample Service | |
| Requirements Overlaid on Service Latency Distribution for Sample Solution | |
| Maximum Acceptable Service Latency | |
| Downtime of Simplex Systems | |
| Downtime of Redundant Systems | |
| Simplified View of High Availability | |
| High Availability Example | |
| Disaster Recovery Objectives | |
| ITU-T G.114 Bearer Delay Guideline | |
| TL 9000 Outage Attributability Overlaid on Augmented 8i + 2d Framework | |
| Outage Responsibilities Overlaid on Cloud 8i + 2d Framework | |
| ITIL Service Management Visualization | |
| IT Service Management Activities to Minimize Service Availability Risk | |
| 8i + 2d Attributability by Process or Best Practice Areas | |
| Traditional Error Vectors | |
| IaaS Provider Responsibilities for Traditional Error Vectors | |
| Software Supplier (and SaaS) Responsibilities for Traditional Error Vectors | |
| Sample Reliability Block Diagram | |
| Traversal of Sample Reliability Block Diagram | |
| Nominal System Reliability Block Diagram | |
| Reliability Block Diagram of Full virtualization | |
| Reliability Block Diagram of OS Virtualization | |
| Reliability Block Diagram of Paravirtualization | |
| Reliability Block Diagram of Coresident Application Deployment | |
| Canonical Virtualization RBD | |
| Latency of Traditional Recovery Options | |
| Traditional Active-Standby Redundancy via Active VM Virtualization | |
| Reboot of a Virtual Machine | |
| Reset of a Virtual Machine | |
| Redundancy via Paused VM Virtualization | |
| Redundancy via Suspended VM Virtualization | |
| Nominal Recovery Latency of Virtualized and Traditional Options | |
| Server Consolidation Using Virtualization | |
| Simplified Simplex State Diagram | |
| Downtime Drivers for Redundancy Pairs | |
| Hardware Failure Rate Questions | |
| Application Reliability Block Diagram with Virtual Devices | |
| Virtual CPU | |
| Virtual NIC | |
| Sample Application Resource Utilization by Time of Day | |
| Example of Extraordinary Event Traffic Spike | |
| The Slashdot Effect: Traffic Load Over Time (in Hours) | |
| Offered Load, Service Reliability, and Service Availability of a Traditional System | |
| Visualizing VM Growth Scenarios | |
| Nominal Capacity Model | |
| Implementation Architecture of Compute Capacity Model | |
| Orderly Reconfiguration of the Capacity Model | |
| Slew Rate of Square Wave Amplification | |
| Slew Rate of Rapid Elasticity | |
| Elasticity Timeline by ODCA SLA Level | |
| Capacity Management Process | |
| Successful Cloud Elasticity | |
| Elasticity Failure Model | |
| Virtualized Application Instance Failure Model | |
| Canonical Capacity Management Failure Scenarios | |
| ITU X.805 Security Dimensions, Planes, and Layers | |
| Leveraging Security and Network Infrastructure to Mitigate Overload Risk | |
| Service Orchestration | |
| Example of Cloud Bursting | |
| Canonical Single Data Center Application Deployment Architecture | |
| RBD of Sample Application on Blade-Based Server Hardware | |
| RBD of Sample Application on IaaS Platform | |
| Sample End-to-End Solution | |
| Sample Distributed Cloud Architecture | |
| Sample Recovery Scenario in Distributed Cloud Architecture | |
| Simplified Responsibilities for a Canonical Cloud Application | |
| Recommended Cloud-Related Service Availability Measurement Points | |
| Canonical Example of MP 1 and MP 2 | |
| End-to-End Service Availability Key Quality Indicators | |
| Virtual Machine Live Migration | |
| Active–Standby Markov Model | |
| Pie Chart of Canonical Hardware Downtime Prediction | |
| RBD for the Hypothetical Web Server Application | |
| Horizontal Growth of Hypothetical Application | |
| Outgrowth of Hypothetical Application | |
| Aggressive Protocol Retry Strategy | |
| Data Replication of Hypothetical Application | |
| Disaster Recovery of Hypothetical Application | |
| Optimal Availability Architecture of Hypothetical Application | |
| Traditional Design for Reliability Process | |
| Mapping Virtual Machines across Hypervisors | |
| A Virtualized Server Failure Scenario | |
| Robustness Testing Vectors for Virtualized Applications | |
| System Design for Reliability as a Deming Cycle | |
| Solution Design for Reliability | |
| Sample Solution Scope and KQI Expectations | |
| Sample Cloud Data Center RBD | |
| Estimating MP 2 | |
| Modeling Cloud-Based Solution with Client-Initiated Recovery Model | |
| Client-Initiated Recovery Model | |
| Failure Impact Duration and High Availability Goals | |
| Eight-Ingredient Plus Data Plus Disaster (8i + 2d) Model | |
| Traditional Outage Attributability | |
| Sample Outage Accountability Model for Cloud Computing | |
| Outage Responsibilities of Cloud by Process | |
| Measurement Pointss (MPs) 1, 2, 3, and 4 | |
| Design for Reliability of Cloud-Based Solutions |
TABLES
| Comparison of Server Virtualization Technologies | |
| Virtual Machine Lifecycle Transitions | |
| Service Availability and Downtime Ratings | |
| Mean Opinion Scores | |
| ODCA’s Data Center Classification | |
| ODCA’s Data Center Service Availability Expectations by Classification | |
| Example Failure Mode Effects Analysis | |
| Failure Mode Effect Analysis Figure for Coresident Applications | |
| Comparison of Nominal Software Availability Parameters | |
| Example of Hardware Availability as a Function of MTTR/MTTRS | |
| ODCA IaaS Elasticity Objectives | |
| ODCA IaaS Recoverability Objectives | |
| Sample Traditional Five 9’s Downtime Budget | |
| Sample Basic Virtualized Five 9’s Downtime Budget | |
| Canonical Application-Attributable Cloud-Based Five 9’s Downtime Budget | |
| Evolution of Sample Downtime Budgets | |
| Example Service Transition Activity Failure Mode Effect Analysis | |
| Canonical Hardware Downtime Prediction | |
| Summary of Hardware Downtime Mitigation Techniques for Cloud Computing | |
| Sample Service Latency and Reliability Requirements at MP 2 | |
| Sample Solution Latency and Reliability Requirements | |
| Modeling Input Parameters | |
| Evolution of Sample Downtime Budgets |
EQUATIONS
| Basic Availability Formula | |
| Practical System Availability Formula | |
| Standard Availability Formula | |
| Estimation of System Availability from MTBF and MTTR | |
| Recommended Service Availability Formula | |
| Sample Partial Outage Calculation | |
| Service Reliability Formula | |
| DPM Formula | |
| Converting DPM to Service Reliability | |
| Converting Service Reliability to DPM | |
| Sample DPM Calculation | |
| Availability as a Function of MTBF/MTTR | |
| Maximum Theoretical Availability across Redundant Elements | |
| Maximum Theoretical Service Availability |
INTRODUCTION
Cloud computing is a new paradigm for delivering information services to end users, offering distinct advantages over traditional IS/IT deployment models, including being more economical and offering a shorter time to market. Cloud computing is defined by a handful of essential characteristics: on-demand self service, broad network access, resource pooling, rapid elasticity, and measured service. Cloud providers offer a variety of service models, including infrastructure as a service, platform as a service, and software as a service; and cloud deployment options include private cloud, community cloud, public cloud and hybrid clouds. End users naturally expect services offered via cloud computing to deliver at least the same service reliability and service availability as traditional service implementation models. This book analyzes the risks to cloud-based application deployments achieving the same service reliability and availability as traditional deployments, as well as opportunities to improve service reliability and availability via cloud deployment. We consider the service reliability and service availability risks from the fundamental definition of cloud computing—the essential characteristics—rather than focusing on any particular virtualization hypervisor software or cloud service offering. Thus, the insights of this higher level analysis and the recommendations should apply to all cloud service offerings and application deployments. This book also offers recommendations on architecture, testing, and engineering diligence to assure that cloud deployed applications meet users’ expectations for service reliability and service availability.
Virtualization technology enables enterprises to move their existing applications from traditional deployment scenarios in which applications are installed directly on native hardware to more evolved scenarios that include hardware independence and server consolidation. Use of virtualization technology is a common characteristic of cloud computing that enables cloud service providers to better manage usage of their resource pools by multiple cloud consumers. This book also considers the reliability and availability risks along this evolutionary path to guide enterprises planning the evolution of their application to virtualization and on to full cloud computing enablement over several releases.
The book is intended for IS/IT system and solution architects, developers, and engineers, as well as technical sales, product management, and quality management professionals.
The book is organized into three parts: Part I, “Basics,” Part II, “Analysis,” and Part III—,“Recommendations.” Part I, “Basics,” defines key terms and concepts of cloud computing, virtualization, service reliability, and service availability. Part I contains three chapters:
Part II, “Analysis,” methodically analyzes the service reliability and availability risks inherent in application deployments on cloud computing and virtualization technology based on the essential and common characteristics given in Part I.
Part III, “Recommendations,” considers techniques to maximize service reliability and service availability of applications deployed on clouds, as well as the design for reliability diligence to assure that virtualized applications and cloud based solutions meet or exceed the service reliability and availability of traditional deployments.
The authors were greatly assisted by many deeply knowledgeable and insightful engineers at Alcatel-Lucent, especially: Mark Clougherty, Herbert Ristock, Shawa Tam, Rich Sohn, Bernard Bretherton, John Haller, Dan Johnson, Srujal Shah, Alan McBride, Lyle Kipp, and Ted East. Joe Tieu, Bill Baker, and Thomas Voith carefully reviewed the early manuscript and provided keen review feedback. Abhaya Asthana, Kasper Reinink, Roger Maitland, and Mark Cameron provided valuable input. Gary McElvany raised the initial architectural questions that ultimately led to this work. This work would not have been possible without the strong management support of Tina Hinch, Werner Heissenhuber, Annie Lequesne, Vickie Owens-Rinn, and Dor Skuler.
Cloud computing is an exciting, evolving technology with many avenues to explore. Readers with comments or corrections on topics covered in this book, or topics for a future edition of this book, are invited to send email to the authors (Eric.Bauer@Alcatel-Lucent.com, Randee.Adams@Alcatel-Lucent.com, or pressbooks@ieee.org).
Eric Bauer
Randee Adams
I
BASICS
1
CLOUD COMPUTING
The U.S. National Institute of Standards and Technology (NIST) defines cloud computing as follows:
Cloud computing is a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction
[NIST-800-145].
This definition frames cloud computing as a “utility” (or a “pay as you go”) consumption model for computing services, similar to the utility model deployed for electricity, water, and telecommunication service. Once a user is connected to the computing (or telecommunications, electricity, or water utility) cloud, they can consume as much service as they would like whenever they would like (within reasonable limits), and are billed for the resources consumed. Because the resources delivering the service can be shared (and hence amortized) across a broad pool of users, resource utilization and operational efficiency can be higher than they would be for dedicated resources for each individual user, and thus the price of the service to the consumer may well be lower from a cloud/utility provider compared with the alternative of deploying and operating private resources to provide the same service. Overall, these characteristics facilitate outsourcing production and delivery of these crucial “utility” services. For example, how many individuals or enterprises prefer to generate all of their own electricity rather than purchasing it from a commercial electric power supplier?
This chapter reviews the essential characteristics of cloud computing, as well as several common characteristics of cloud computing, considers how cloud data centers differ from traditional data centers, and discusses the cloud service and cloud deployment models. The terminologies for the various roles in cloud computing that will be used throughout the book are defined. The chapter concludes by reviewing the benefits of cloud computing.
Per [NIST-800-145], there are five essential functional characteristics of cloud computing:
Each of these is considered individually.
Per [NIST-800-145], the essential cloud characteristic of “on-demand self-service” means “a consumer can unilaterally provision computing capabilities, such as server time and network storage, as needed automatically without requiring human interaction with each service’s provider.” Modern telecommunications networks offer on-demand self service: one has direct dialing access to any other telephone whenever one wants. This behavior of modern telecommunications networks contrasts to decades ago when callers had to call the human operator to request the operator to place a long distance or international call on the user’s behalf. In a traditional data center, users might have to order server resources to host applications weeks or months in advance. In the cloud computing context, on-demand self service means that resources are “instantly” available to service user requests, such as via a service/resource provisioning website or via API calls.
Per [NIST-800-145] “broad network access” means “capabilities are available over the network and accessed through standard mechanisms that promote use by heterogeneous thin or thick client platforms (e.g., mobile phones, laptops, and PDAs).” Users expect to access cloud-based services anywhere there is adequate IP networking, rather than requiring the user to be in a particular physical location. With modern wireless networks, users expect good quality wireless service anywhere they go. In the context of cloud computing, this means users want to access the cloud-based service via whatever wireline or wireless network device they wish to use over whatever IP access network is most convenient.
Per [NIST-800-145], the essential characteristic of “resource pooling” is defined as: “the provider’s computing resources are pooled to serve multiple consumers using a multi-tenant model, with different physical and virtual resources dynamically assigned and reassigned according to consumer demand.” Service providers deploy a pool of servers, storage devices, and other data center resources that are shared across many users to reduce costs to the service provider, as well as to the cloud consumers that pay for cloud services. Ideally, the cloud service provider will intelligently select which resources from the pool to assign to each cloud consumer’s workload to optimize the quality of service experienced by each user. For example, resources located on servers physically close to the end user (and which thus introduce less transport latency) may be selected, and alternate resources can be automatically engaged to mitigate the impact of a resource failure event. This is essentially the utility model applied to computing. For example, electricity consumers don’t expect that a specific electrical generator has been dedicated to them personally (or perhaps to their town); they just want to know that their electricity supplier has pooled the generator resources so that the utility will reliably deliver electricity despite inevitable failures, variations in load, and glitches.
Computing resources are generally used on a very bursty basis (e.g., when a key is pressed or a button is clicked). Timeshared operating systems were developed decades ago to enable a pool of users or applications with bursty demands to efficiently share a powerful computing resource. Today’s personal computer operating systems routinely support many simultaneous applications on a PC or laptop, such as simultaneously viewing multiple browser windows, doing e-mail, and instant messaging, and having virus and malware scanners running in the background, as well as all the infrastructure software that controls the keyboard, mouse, display, networking, real-time clock, and so on. Just as intelligent resource sharing on your PC enables more useful work to be done cost effectively than would be possible if each application had a dedicated computing resource, intelligent resource sharing in a computing cloud environment enables more applications to be served on less total computing hardware than would be required with dedicated computing resources. This resource sharing lowers costs for the data center hosting the computing resources for each application, and this enables lower prices to be charged to cloud consumers than would be possible for dedicated computing resources.
[NIST-800-145] describes “rapid elasticity” as “capabilities can be rapidly and elastically provisioned, in some cases automatically, to quickly scale out, and rapidly released to quickly scale in. To the consumer, the capabilities available for provisioning often appear to be unlimited and can be purchased in any quantity at any time.”
Forecasting future demand is always hard, and there is always the risk that unforeseen events will change plans and thereby increase or decrease the demand for service. For example, electricity demand spikes on hot summer afternoons when customers crank up their air conditioners, and business applications have peak usage during business hours, while entertainment applications peak in evenings and on weekends. In addition, most application services have time of day, day of week, and seasonal variations in traffic volumes. Elastically increasing service capacity during busy periods and releasing capacity during off-peak periods enables cloud consumers to minimize costs while meeting service quality expectations. For example, retailers might experience heavy workloads during the holiday shopping season and light workloads the rest of the year; elasticity enables them to pay only for the computing resources they need in each season, thereby enabling computing expenses to track more closely with revenue. Likewise, an unexpectedly popular service or particularly effective marketing campaign can cause demand for a service to spike beyond planned service capacity. End users expect available resources to “magically” expand to accommodate the offered service load with acceptable service quality. For cloud computing, this means all users are served with acceptable service quality rather than receiving “busy” or “try again later” messages, or experiencing unacceptable service latency or quality.
Just as electricity utilities can usually source additional electric power from neighboring electricity suppliers when their users’ demand outstrips the utility’s generating capacity, arrangements can be made to overflow applications from one cloud that is operating at capacity to other clouds that have available capacity. This notion of gracefully overflowing application load from one cloud to other clouds is called “cloud bursting.”
[NIST-800-145] describes the essential cloud computing characteristic of “measured service” as “cloud systems automatically control and optimize resource use by leveraging a metering capability at some level of abstraction appropriate to the type of service (e.g., storage, processing, bandwidth, and active user accounts). Resource usage can be monitored, controlled, and reported, providing transparency for both the provider and the consumer of the utilized service.” Cloud consumers want the option of usage-based (or pay-as-you-go) pricing in which their price is based on the resources actually consumed, rather than being locked into a fixed pricing arrangement. Measuring resource consumption and appropriately charging cloud consumers for their actual resource consumption encourages them not to squander resources and release unneeded resources so they can be used by other cloud consumers.
NIST originally included eight common characteristics of cloud computing in their definition [NIST-B], but as these characteristics were not essential, they were omitted from the formal definition of cloud computing. Nevertheless, six of these eight common characteristics do impact service reliability and service availability, and thus will be considered later in this book.
Fundamentally, cloud computing is a new business model for operating data centers. Thus, one can consider cloud computing in two steps:
A data center is a physical space that is environmentally controlled with clean electrical power and network connectivity that is optimized for hosting servers. The temperature and humidity of the data center environment are controlled to enable proper operation of the equipment, and the facility is physically secured to prevent deliberate or accidental damage to the physical equipment. This facility will have one or more connections to the public Internet, often via redundant and physically separated cables into redundant routers. Behind the routers will be security appliances, like firewalls or deep packet inspection elements, to enforce a security perimeter protecting servers in the data center. Behind the security appliances are often load balancers which distribute traffic across front end servers like web servers. Often there are one or two tiers of servers behind the application front end like second tier servers implementing application or business logic and a third tier of database servers. Establishing and operating a traditional data center facility—including IP routers and infrastructure, security appliances, load balancers, servers’ storage and supporting systems—requires a large capital outlay and substantial operating expenses, all to support application software that often has widely varying load so that much of the resource capacity is often underutilized.
The Uptime Institute [Uptime and TIA942] defines four tiers of data centers that characterize the risk of service impact (i.e., downtime) due to both service management activities and unplanned failures:
Tier I “basic” data centers must be completely shut down to execute planned and preventive maintenance, and are fully exposed to unplanned failures. [UptimeTiers] offers “Tier 1 sites typically experience 2 separate 12-hour, site-wide shutdowns per year for maintenance or repair work. In addition, across multiple sites and over a number of years, Tier I sites experience 1.2 equipment or distribution failures on an average year.” This translates to a data center availability rating of 99.67% with nominally 28.8 hours of downtime per year.
Tier II “redundant component” data centers include some redundancy and so are less exposed to service downtime. [UptimeTiers] offers “the redundant components of Tier II topology provide some maintenance opportunity leading to just 1 site-wide shutdown each year and reduce the number of equipment failures that affect the IT operations environment.” This translates to a data center availability rating of 99.75% with nominally 22 hours of downtime per year.
Tier III “concurrently maintainable” data centers are designed with sufficient redundancy that all service transition activities can be completed without disrupting service. [UptimeTiers] offers “experience in actual data centers shows that operating better maintained systems reduces unplanned failures to a 4-hour event every 2.5 years. … ” This translates to a data center availability rating of 99.98%, with nominally 1.6 hours of downtime per year.
Tier IV “fault tolerant” data centers are designed to withstand any single failure and permit service transition type activities, such as software upgrade to complete with no service impact. [UptimeTiers] offers “Tier IV provides robust, Fault Tolerant site infrastructure, so that facility events affecting the computer room are empirically reduced to (1) 4-hour event in a 5 year operating period. … ” This translates to a data center availability rating of 99.99% with nominally 0.8 hours of downtime per year.
Not only are data centers expensive to build and maintain, but deploying an application into a data center may mean purchasing and installing the computing resources to host that application. Purchasing computing resources implies a need to do careful capacity planning to decide exactly how much computing resource to invest in; purchase too little, and users will experience poor service; purchase too much and excess resources will be unused and stranded. Just as electrical power utilities pool electric power-generating capacity to offer electric power as a service, cloud computing pools computing resources, offers those resources to cloud consumers on-demand, and bills cloud consumers for resources actually used. Virtualization technology makes operation and management of pooled computing resources much easier. Just as electric power utilities gracefully increase and decrease the flow of electrical power to customers to meet their individual demand, clouds elastically grow and shrink the computing resources available for individual cloud consumer’s workloads to match changes in demand. Geographic distribution of cloud data centers can enable computing services to be offered physically closer to each user, thereby assuring low transmission latency, as well as supporting disaster recovery to other data centers. Because multiple applications and data sets share the same physical resources, advanced security is essential to protect each cloud consumer. Massive scale and homogeneity enable cloud service providers to maximize efficiency and thus offer lower costs to cloud consumers than traditional or hosted data center options. Resilient computing architectures become important because hardware failures are inevitable, and massive data centers with lots of hardware means lots of failures; resilient computing architectures assure that those hardware failures cause minimal service disruption. Thus, the difference between a traditional data center and a cloud computing data center is primarily the business model along with the policies and software that support that business model.
NIST defines three service models for cloud computing: infrastructure as a service, platform as a service, and software as a service. These cloud computing service models logically sit above the IP networking infrastructure, which connects end users to the applications hosted on cloud services. visualizes the relationship between these service models.
Service Models.
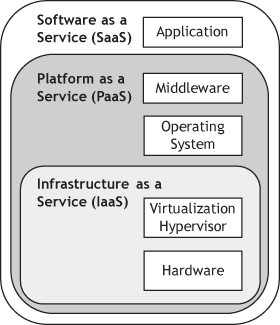
The cloud computing service models are formally defined as follows.
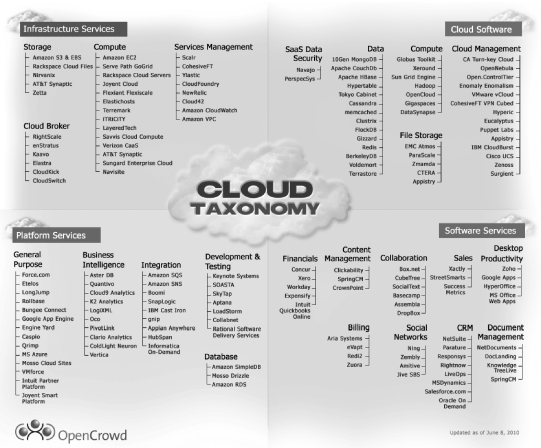
gives concrete examples of IaaS, PaaS, and SaaS offerings.
OpenCrowd’s Cloud Taxonomy.
Source: Copyright 2010, Image courtesy of OpenCrowd, opencrowd.com.
NIST recognizes four cloud deployment models:
Cloud service providers typically offer either private, community or public clouds, and cloud consumers select which of those three to use, or adopt a hybrid deployment strategy blending private, community and/or public clouds.
Cloud computing opens up interfaces between applications, platform, infrastructure, and network layers, thereby enabling different layers to be offered by different service providers. While NIST [NIST-C] and some other organizations propose new roles of cloud service consumers, cloud service distributors, cloud service developers and vendors, and cloud service providers, the authors will use the more traditional roles of suppliers, service providers, cloud consumers, and end users, as illustrated in .
Roles in Cloud Computing.
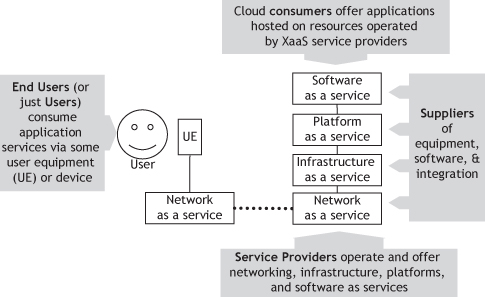
Specific roles in are defined below.